
How the AKASA Engineering Team Created an Automation Solution for Database Migrations
Streamlining Postgres migrations for increased developer proficiency.
The Gist
AKASA went from a very manual db migrations process to an automated database migration system. Using the open-source tools Migra, Sql-Migrate, and GitHub actions, we created a workflow that generates and applies migrations to our fleet of database instances whenever an engineer makes a database schema change. A huge friction point for engineers was removed, and the safety and integrity of client data were improved.
AKASA builds products and tools to improve the various components of revenue cycle management (medical billing) for hospital systems. Most of these solutions involve advanced automation.
For all our products, we primarily use Postgres to manage state, with SQLAlchemy as the framework for schema management and Alembic for generating migrations. To best serve our clients, we have a separate database instance per client with a shared schema.
As we scaled the business, we needed automated database migrations to manage generating and applying migrations to our client Postgres instances. Here’s a deep dive into that process.
Existing Operations
We have two environments: prod and staging.
In prod, an engineer working on a feature that needs a new table (or modification to an existing table) would make a PR. Along with that PR, they would:
- Add or update the schema’s SQLAlchemy Python class.
- Generate a migration via Alembic that would run against an existing production db as a source of truth.
- Make manual changes to the generated migration script when dealing with cases Alembic doesn’t handle well: Enum creation, column renames, etc.
- Wait for the PR with the schema change and migration to be approved and merged.
- Coordinate with a db admin (in the migrations Slack channel) to request running the migration deployment script across all the client instances. Understandably, we keep this set of people with admin permissions as minimal as possible.
If an engineer wanted the latest schema applied to the staging environment, they would run the prod-generated Alembic migration against the staging instance. Sometimes, this would involve manually changing the Alembic version on the staging instance to comply. Engineers can make manual schema changes on an ad hoc basis for testing new features. Sometimes, they would revert or modify changes to allow the migration to go through.
All of these manual steps and coordination resulted in a time-consuming process with opportunities for errors. We needed a better way.
Goals of the Project
As an organization, we try to minimize friction for our engineers. This gives them more time to focus on the problems that matter — to our company and clients. This migration project aimed to enhance developer productivity by establishing an accessible but powerful platform.
The continued integrity of our client data was also top-of-mind. Having an automated process around managing data schemas removes risks of human error and the scope of variables that could affect client data.
Here are some of the specific goals we set out at the beginning of our efforts:
- Engineers should be able to make schema changes without worrying about generating or applying migrations.
- Migrations themselves should be automatically generated and applied to all client instances.
- Engineers should be able to change the generated migrations manually if needed.
- Generated migrations should be agnostic to the framework used for schema management. Ideally, this would be in SQL.
- The safety of clients’ data is of the utmost concern. The framework should protect against corruption and detect any changes being made to prod databases that don’t align with the SQLAlchemy schema.
- The source of truth for generating migrations should be the schema. There should be no dependencies on production systems.
- There should be a migration history and the ability to revert a migration.
- There should be first-class support for keeping staging databases in sync with prod and allowing easy schema changes for testing new features.
The Main Components for the New Design
Migra: An elegant Postgres-specific framework for generating db migrations. It operates similarly to the Linux diff command. Given two database connections (A and B), Migra will “diff” the two to generate a migration that takes A → B. It generates the migration in PostgreSQL, and (since it’s made for Postgres) it handles everything out of the box. For our use cases, this meant no more manual modifications.
SQL-Migrate: Manages applying migrations to a database. It maintains the state for migrations that have been run and will apply any remaining migrations. The order in which migrations are applied is defined through the file name, for which we chose an increasing version number at the beginning of the file. Syntax like — +migrate Up and — +migrate Down allow specifying the migration and a revert. Migrations themselves are applied as a transaction.
Design
There were three main components we created for automating migrations:
- Create migration: Generates a new migration PR when a change is made to the db_schema git repository.
- Verify migration: Verifies that the migration PR is consistent with the db_schema git repository. This allows safe, manual changes to the PR.
- Apply migration: Applies the migration to all client dbs. Before application, it ensures that the client_db hasn’t been diverted in any way from the version it’s on.
When combined, these form a cohesive workflow orchestrated using GitHub Actions.
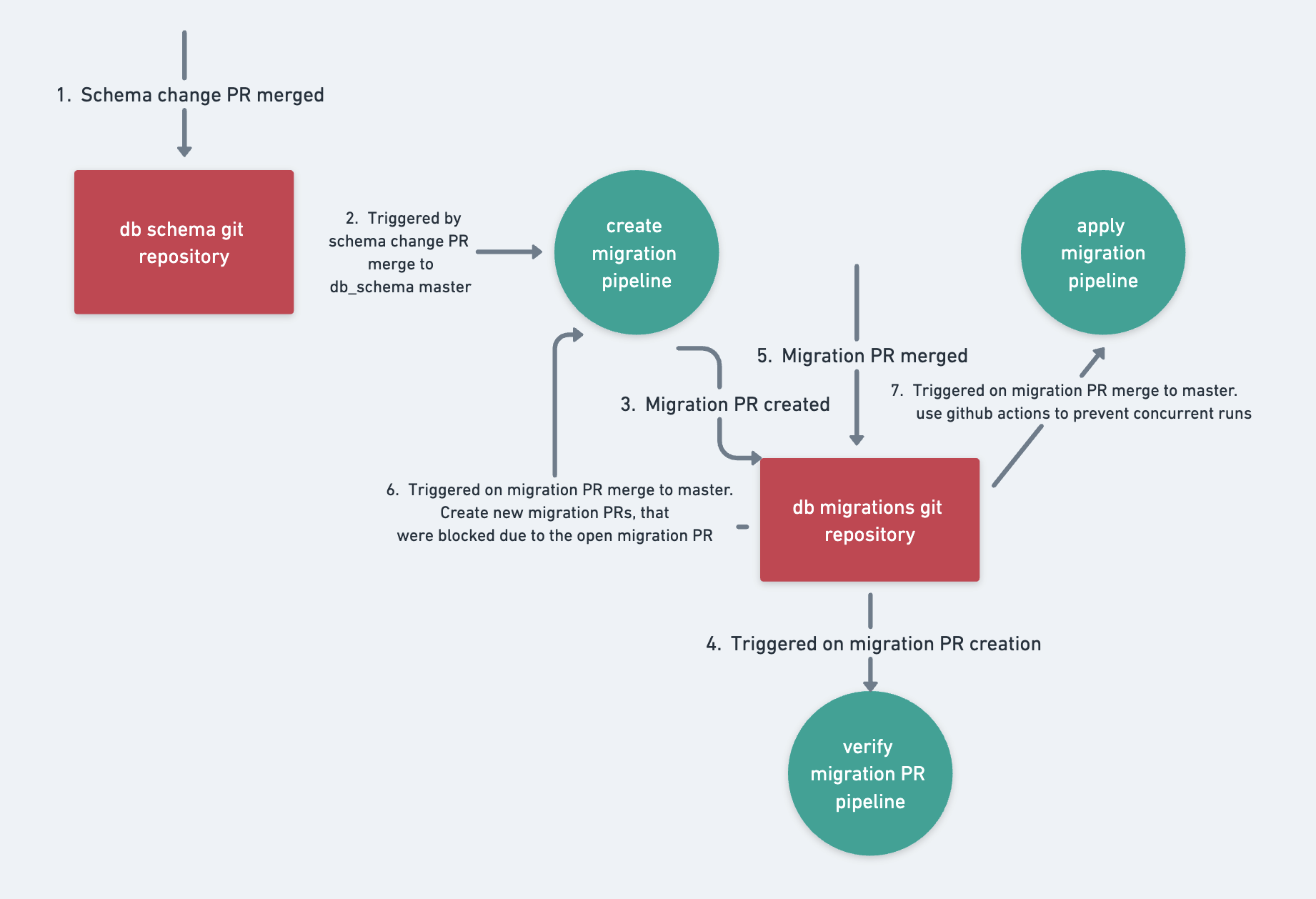
Create migration
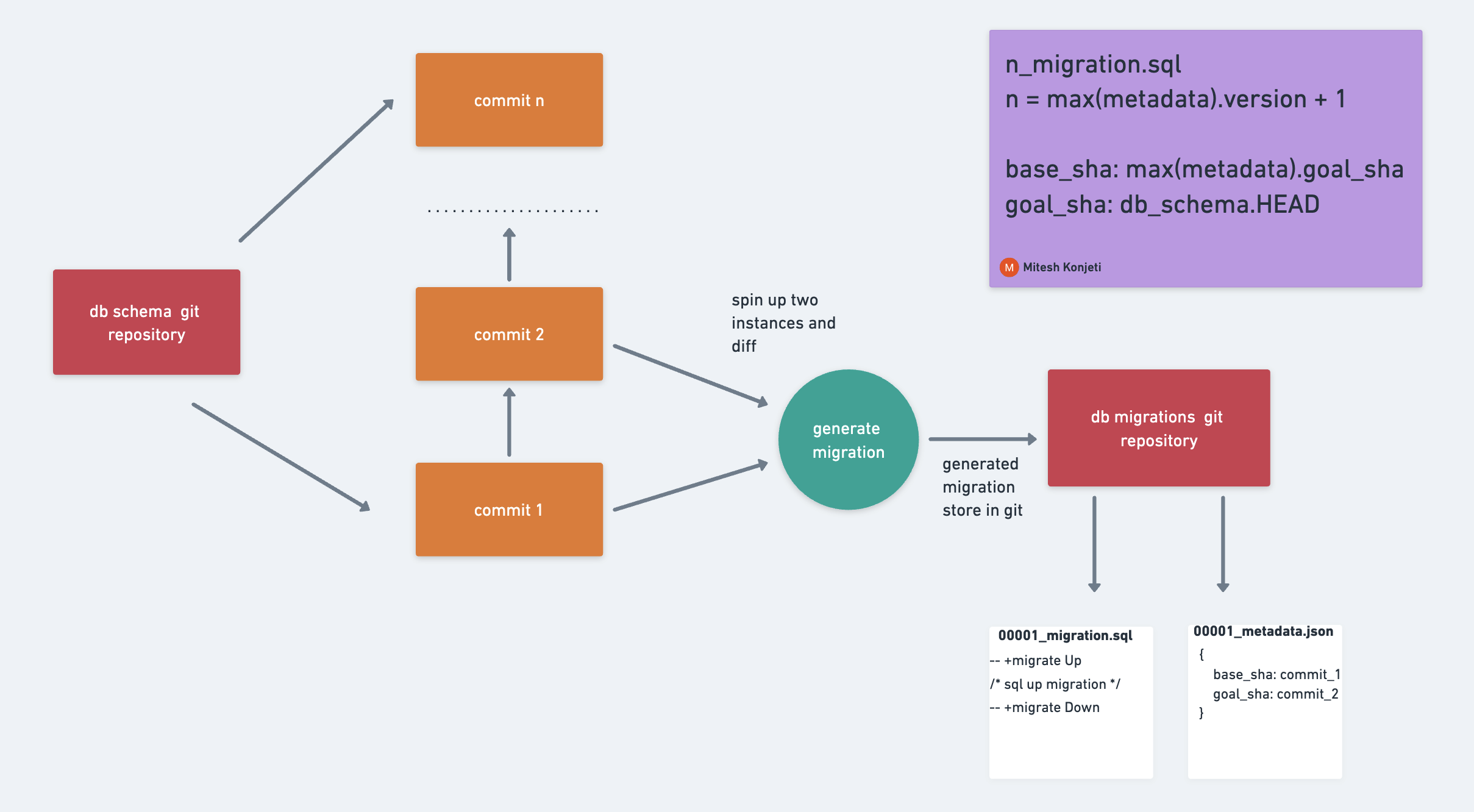
(Moving forward, we’ll refer to SHAs — the term we use for the git commit version.)
Migra is capable of generating a migration given two different database connections. We can spin up a database container with docker, and (given a db_schema git SHA) we can create all the tables using SQLAlchemy. Generating a migration is more of a question of what db_schema SHAs we’re comparing.
The db_migration repo maintains the state to answer this question. It keeps track of all the migrations generated and all of the SHAs associated with that migration — with metadata files containing the base_sha and goal_sha.
When a new commit is merged to the db_schema git repository, the new goal_sha is HEAD and the new base_sha is the previous metadata version’s goal_sha. This serves as the contents of our new metadata.json file. We spin up two new dbs and generate a diff from base_sha → goal_sha. From this diff, we create a new migration.sql file.
Because we’re automatically generating migration PRs, we want to defend against any odd merges. The solution is to have the new migration and metadata files always be the latest version_number + 1. The version_number + 1 strategy is a form of optimistic locking. It’s a simple but powerful method to provide safety. If many PRs are generated at different times, only one can win the merge — with the others getting conflicts.
As an added measure of simplicity, we prevent multiple PRs from being generated by always checking if there’s an outstanding PR before generating a new one.
To prevent lagging PRs, we trigger a create migration (step 6 in the workflow design diagram) again whenever a migration is merged — in case a new PR was stopped due to an outstanding migration.
Verify migration
The generated migration PR enables manual changes. Therefore, we always need to ensure the proposed migration is consistent with the schema for the database.
Theoretically, we could have bypassed the PR process and merged migrations directly. However, the PR process offers several benefits. For example, it allows an engineer to specify the creation of a new index concurrently. More importantly, it provides an additional layer of safety.
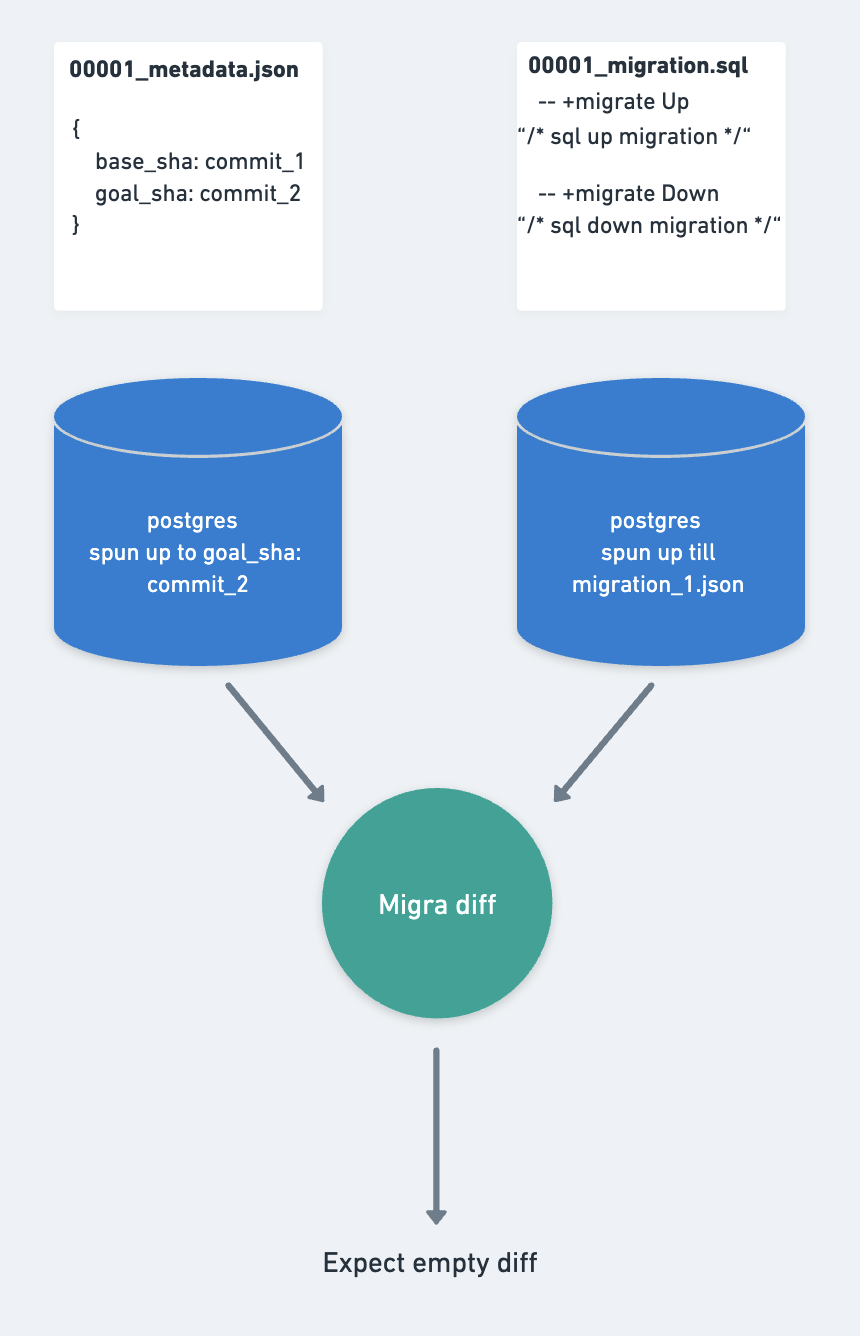
We spin up a database using SQLAlchemy with the goal_sha of the PR. Additionally, we create a second database using only the migration files, employing SQL-Migrate. We use Migra to compare these two databases. If a difference is detected, it indicates that the introduced manual change in the migration file is inconsistent with the db schema. As a result, merging the PR is not permitted.
Apply migration
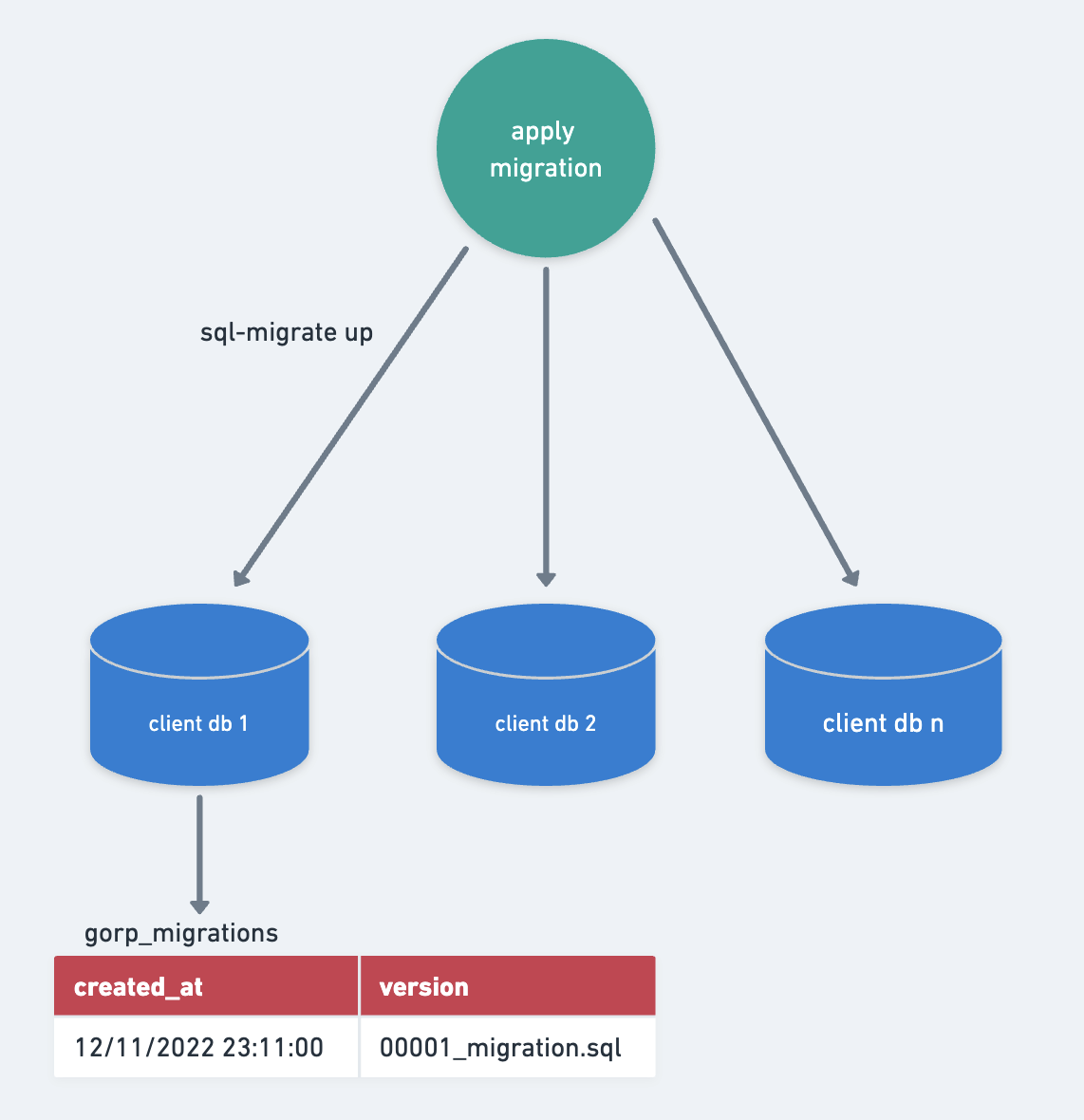
The migrations are applied independently to all client databases in parallel using the migration files from the db_migrations git repository and SQL-Migrate. These migrations are applied within a transaction and can be safely retried until no migrations remain.
Before applying any migration, it is essential to perform a consistency check. This step is crucial because when we apply migration version n+1, we assume the database is currently at migration version n. Any unexpected changes could impact the accuracy of the migration process.
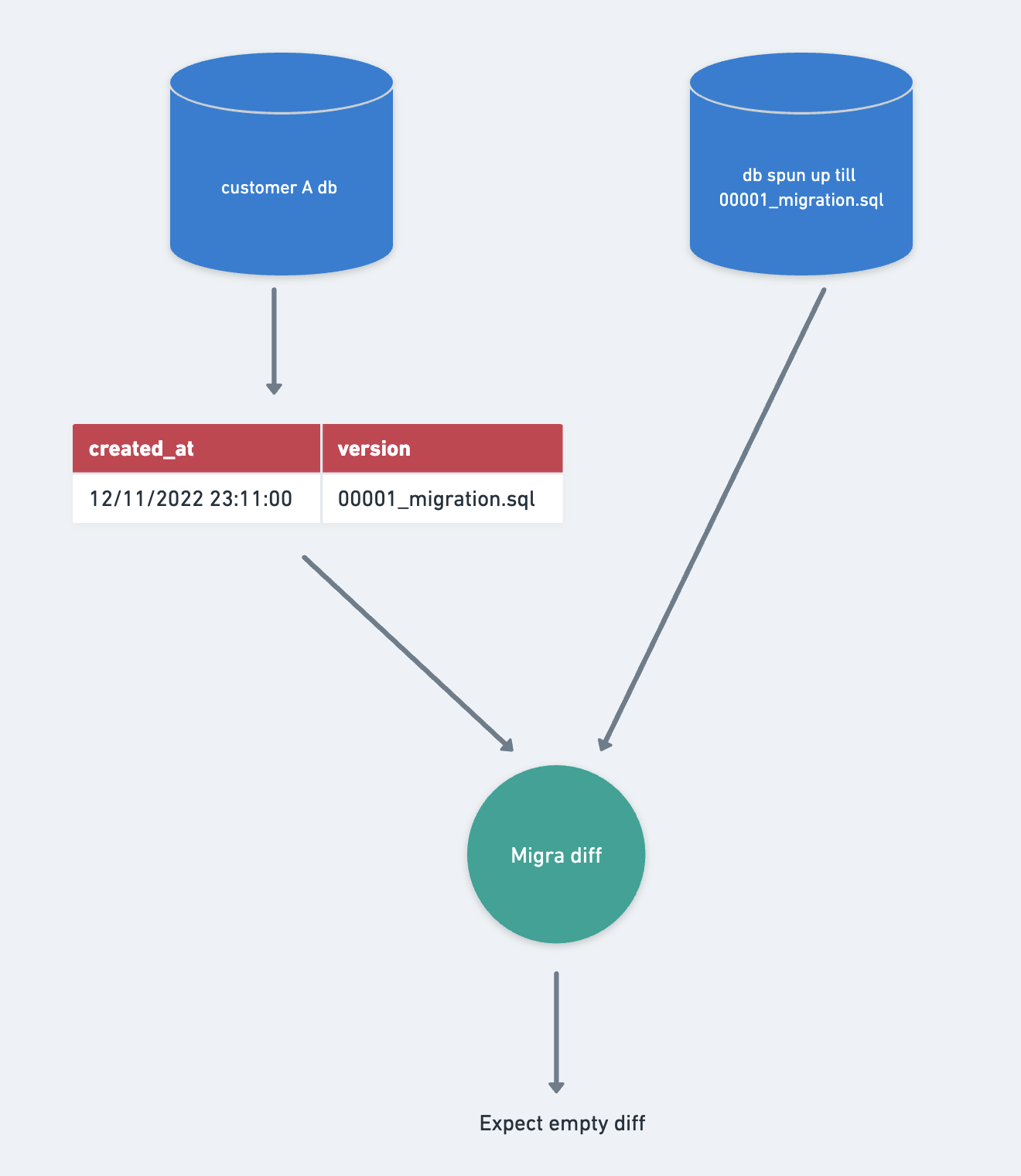
The consistency check verifies that the client database is in sync with the version it should be on. If it turns out that this is not the case, we postpone the client database’s migration until the inconsistency has been resolved.
Such situations should be exceptionally rare. Write permissions to the databases are highly restricted, and access requirements are in place to minimize the likelihood of discrepancies.
Having this additional layer of protection is always of paramount importance.
Staging
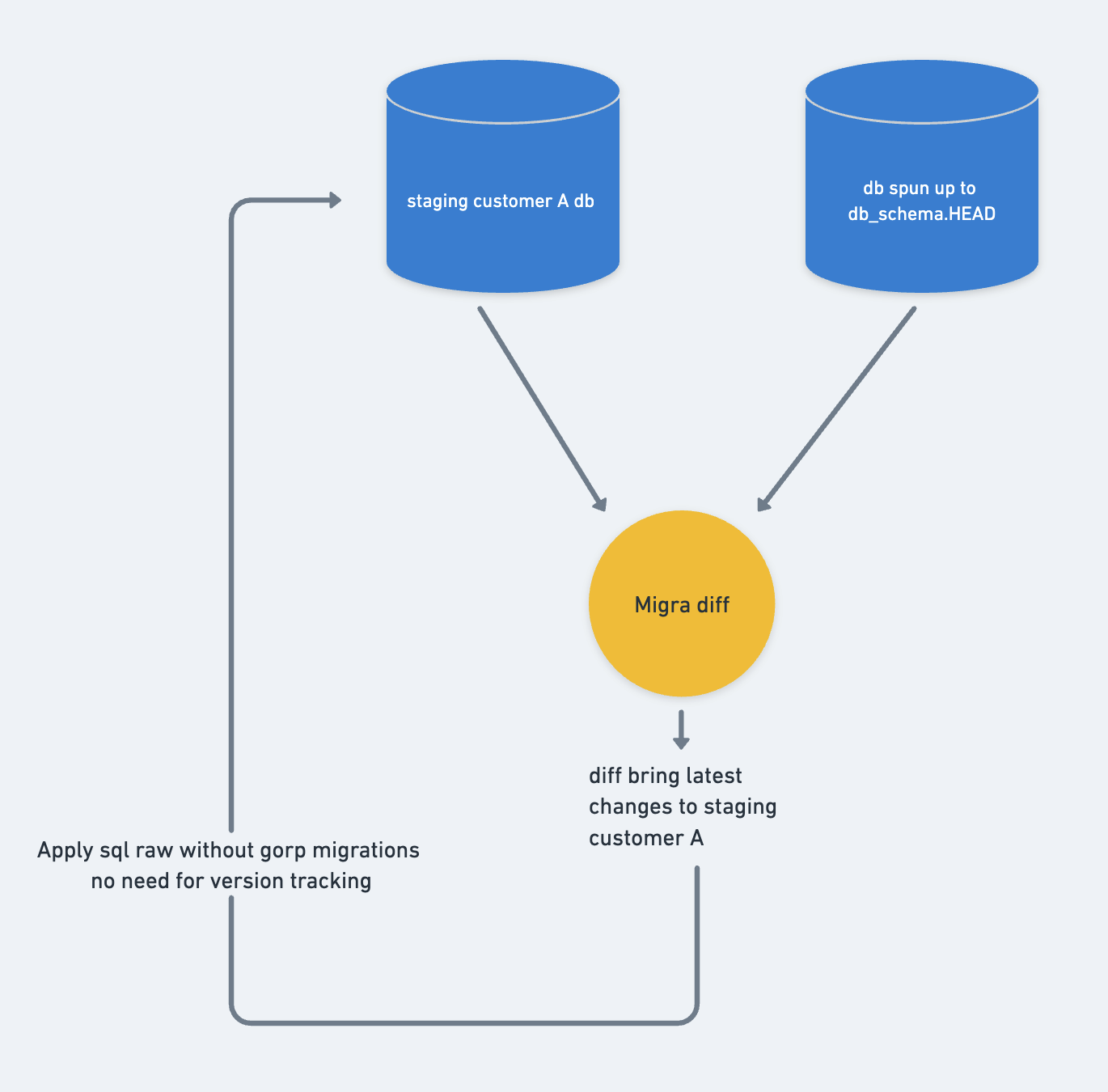
Staging doesn’t require the versioning metadata and rollbacks we use in production, making the solution more straightforward. We execute automated ‘apply_migrations’ against all staging databases, just as with production databases. The pipeline generates an in-place difference between the staging database and the latest db_schema git repository SHA version and applies this SQL within a transaction.
For applying ad-hoc development changes, we offer a Command-Line Interface (CLI). This CLI allows users to specify a custom branch of the db_shema git repository and automatically generates and applies the SQL necessary to synchronize the staging database.
We also run an automated GitHub actions pipeline in production that runs whenever there’s been a merge to master for the db_schema git repository. It runs against all registered staging databases.
A New Migration Process Success
This framework has been running successfully at AKASA for a while now — we’re currently at 160 migrations and counting. It has significantly improved the speed and safety of database migrations within the company.
Manual modifications to PRs have proven rare. In most cases, engineers perform a quick verification to ensure that the PR aligns with its intended purpose and then proceed to merge it. Migrations are now an afterthought for our engineers — as they should be on a stable platform. The platform now takes care of ensuring reliability.
The rollout of this platform has been a success. Engineers have generally embraced the platform and appreciated the time and steps it saves them.
Migra and SQL-Migrate are great open-source tools. If your company uses Postgres and has any manual processes around migrations, the tools and patterns used in this post should be useful assets for automating migrations, saving engineers time, and protecting data integrity.

Mitesh Konjeti is a senior software engineer at AKASA. He works on building platforms that scale the business, help clients, and improve developer productivity. Previously Konjeti worked at Uber (on infrastructure, storage, and Uber Eats), Facebook, and Amazon. He has a computer science degree from the University of Illinois Urbana-Champaign.
You may also like
Blog
Feb 20, 2024
How the AKASA Engineering Team Created an Automation Solution for Database Migrations
AKASA builds products and tools to improve the various components of revenue cycle management (medical billing) for hospital systems....
Blog

May 1, 2023
ChatGPT and Healthcare: Exciting Potential That Needs To Be Channeled
Recently I heard that as a fun exercise, the security officer at one of our healthcare clients tried asking...
Blog

Jun 12, 2023
Overcoming the Top 3 Challenges Holding Back Healthcare Innovation
Healthcare is notoriously slow at adapting and incorporating new technologies into day-to-day operations. Healthcare lags behind as one of...
Blog

Jun 12, 2023
7 IT Mistakes You’re Making With Your RCM Automation Partner
The right revenue cycle management (RCM) automation is capable of helping healthcare organizations overcome a litany of issues —...
Blog

Jun 12, 2023
Questions Healthcare IT Teams Should Ask About Revenue Cycle Automation
RCM leaders at your organization are discussing automation. Period. The healthcare revenue cycle is fighting non-stop battles. Staffing challenges...
Blog

Jul 23, 2024
9 Healthcare Technology Trends To Watch
Keeping track of the rapid changes in healthcare technology is no small task. The industry has seen numerous healthcare...
Blog

Nov 30, 2022
The Gradient Podcast: An Interview on AI and Healthcare With AKASA CTO and Co-Founder Varun Ganapathi
On a recent episode of the Gradient Podcast, host Daniel Bashir sat down with AKASA CTO and co-founder, Varun...
Blog

Sep 1, 2022
Machine Learning in Medicine: Using AI to Predict Optimal Treatments
At AKASA, we’re always thinking about how we can use machine learning (ML) and artificial intelligence (AI) to better...