
Blog
How LLMs Upgraded Our Pydantic Implementation With a Shim Library
The Gist
Upgrading from Pydantic v1 to v2 should have been straightforward. It wasn’t.
A subtle incompatibility between dependencies turned into a system-wide coordination problem. One that sat unresolved for years because fixing it risked breaking production.
In this post, we walk through how our engineering team untangled that problem by introducing a shim layer that isolated version differences, enabled gradual migration, and reduced risk. Along the way, we explore what this reveals about building real-world LLM systems, including where the hardest problems aren’t always in the models, but in the infrastructure around them.
By Lucas Wiman, George Bocharov, and the AKASA engineering team
At AKASA, we build large language model (LLM) systems that read and reason over complex clinical data to help health systems operate more efficiently. That means working with messy, high-volume, real-world data, and the infrastructure challenges that come with it.
As these systems scale, small inconsistencies at component boundaries can become real production issues.
Recently, while upgrading part of our stack from Pydantic v1 to v2, we ran into a subtle but high-impact compatibility problem: different parts of our system (and the libraries they depended on) were locked into incompatible versions of the same validation framework.
What looked like a routine migration turned into a coordination problem across dependencies we didn’t fully control. This post walks through what happened, why it was harder than it looked, and how we solved it with a shim layer.
The hidden complexity in a “simple” Pydantic upgrade
In late 2025, we successfully upgraded approximately 20 Python services and libraries from Pydantic 1 to Pydantic 2. The driving force was Pydantic AI, a framework that could improve our Coding Optimizer, but is strictly compatible with Pydantic. This was a non-trivial challenge, with three previous attempts collecting dust as stale PRs.
The individual changes weren't hard. Pydantic 2 renamed a bunch of methods (user.dict() → user.model_dump(), User.parse_obj(...) → User.model_validate(...)) and restructured how model configuration works. Tedious but mechanical. The problem was structural: our services shared a common library of domain models (diagnosis codes, encounters, the core objects of healthcare billing), and you couldn't upgrade any service without upgrading that library. That meant upgrading every service.
"Upgrade everything at once" is not a task that fits in the time slices engineers actually have between product work, so each attempt would get partway through, stall, and eventually go stale as the codebase moved on underneath it.
What eventually worked was reframing the problem. Instead of trying to do the upgrade in a single coordinated push, we built a shim library that let us write Pydantic 2 syntax while running on Pydantic 1. This made the work decomposable into pieces that could be merged to main independently, so progress never went stale. Combined with an AI-generated 1600-line compatibility test suite, this turned a year-long source of frustrating false starts into a few months of part-time incremental work.
Because this sits at the boundary between components, inconsistencies here don’t always fail loudly. They can introduce subtle validation differences that are difficult to detect and even harder to debug in production.
Why we didn’t fix this for two years
Any meaningful fix required coordinated changes across multiple components and dependencies, with a real risk of introducing regressions in production systems. Without a clean migration path, the “do nothing” option was actually rational for a long time.
Pydantic 2.0 shipped in June 2023. We started our upgrade in earnest in 2025. The reason for the gap will be familiar to anyone who's worked on a production codebase: the labor cost of doing the upgrade couldn't be justified against feature work.
This isn't a story about negligence.
Pydantic 1 did its job. It validated the data, integrated with FastAPI, and provided shared domain models across services.
Pydantic 2 did the same job somewhat better (with a Rust-based core for performance, cleaner configuration, and some long-standing design issues fixed). But "somewhat better" doesn't clear the bar when the alternative is shipping product features.
What eventually pushed us over the edge was Pydantic AI, an agent framework built by the same team that was only compatible with Pydantic 2. We wanted to use it for prototyping features in our Coding Optimizer and CDI Optimizer products. So the upgrade went from "important but not urgent" to "blocking the roadmap."
On the surface, this looked like a standard library upgrade. But it exposed a coordination problem across tightly coupled dependencies that were subtly coupled. Fixing it wasn’t just about updating versions. It required maintaining compatibility across systems we didn’t fully control.
The real problem: dependency coordination
As with many kinds of technical debt, some of the difficulty was idiosyncratic to our codebase.
We had a common library containing domain model definitions like DiagnosisCode and Encounter — the objects that represent the core of healthcare revenue cycle management across several generations of products. This library was used by the majority of our services. If we upgraded our domain models, then we would need to upgrade every consumer of them.
If Service1 and Service2 both use common.DiagnosisCode, then to upgrade either service to Pydantic 2, you need to upgrade the common library.
Meaning you need the common library to support both versions simultaneously, you need to upgrade both services at the same time, or you need to freeze one of the services while you work.
In practice, freezing a service is untenable, and the breaking changes in Pydantic 2 made dual-version support nontrivial.
This is the kind of problem that makes dependency upgrades disproportionately expensive in service-oriented architectures. The technical work is simple, but coordination costs dominate.
The pydantic.v1 trap
Pydantic 2 ships with a built-in compatibility layer: the entire Pydantic 1 codebase is vendored under pydantic.v1. The official migration guide suggests changing from pydantic import BaseModel to from pydantic.v1 import BaseModel as a first step. This works for simple cases.
However, it falls apart for anything resembling our setup, for two reasons.
First, you can't meaningfully mix Pydantic 2 models and pydantic.v1 models. Pydantic 2 treats v1 models as arbitrary Python types, which produces confusing stack traces when you try to nest them:
Second, FastAPI dropped support for pydantic.v1.BaseModel. This is understandable — supporting two incompatible model systems is painful. But it meant any domain model exposed through a FastAPI endpoint had to be a real Pydantic 2 model, not a v1 shim.
An early attempt at our upgrade used the pydantic.v1 module for domain models that weren't exposed via FastAPI. We later discovered that this created a second migration: services that had already moved to pydantic.v1 now needed to move again to actual Pydantic 2. Doing so would break them if the common library hadn't been updated yet.
We'd accidentally turned one migration into two.
The solution: a shim layer
Instead of forcing a full migration or trying to align every dependency at once, we took a different approach: we introduced a shim layer to isolate the incompatibility.
The goal was simple: define a stable interface we controlled, and hide the differences between Pydantic versions behind it.
Instead of forcing the ecosystem to align, we adapted to it by decoupling our internal code from external library constraints and gradually migrating toward the newer version.
The approach that eventually worked was inspired by Six, the library that bridged Python 2 and Python 3. Six let you write code in one syntax that ran on both runtimes. This meant you could upgrade files incrementally and merge them to main without breaking anything. We wanted the same thing for Pydantic.
We built pydantic_12_shims, a library that exported Pydantic 2's API surface but implemented it on top of whatever Pydantic version was actually installed. Code that imported from the shims library looked like Pydantic 2 and quacked like Pydantic 2.
Before
After
How the shim actually works
This approach gave us three key benefits:
Compatibility: Both Pydantic v1 and v2 could coexist without breaking dependent components
Gradual migration: We could move pieces of the system over time instead of coordinating a full cutover
Reduced risk: Changes were isolated, minimizing the chance of regressions in production
The key property was that code using the shims could be merged to main and coexist with code that hadn't been updated yet. There was no need for long-running feature branches or spaghetti-code feature flags. Engineers could pick up a service, convert its imports, run the tests, and ship it. Then, they could move on to the next one or go back to product work for a week. When they came back, their previous work was still there, still passing CI, still current with the rest of the codebase.
We also needed to handle the services that had already moved to pydantic.v1. The shim library included a pydantic_12_shims.v1 module that re-exported real Pydantic 2 models or the vendored pydantic.v1 model, controlled by an environment variable TURN_PYDANTIC_V1_OFF. This let us update those services' imports without changing their runtime behavior until we were ready to flip the switch.
One of our engineers had faced a similar problem at a previous company, migrating from Django REST Framework to FastAPI while maintaining a shared codebase for legacy and new customers. His solution was an open-source library, DRF-Pydantic, that lets you declare models as Pydantic and automatically generate DRF serializers from them.
It was the same idea: define things once in the target syntax and shim the legacy system.
At a high level, here’s what changed:
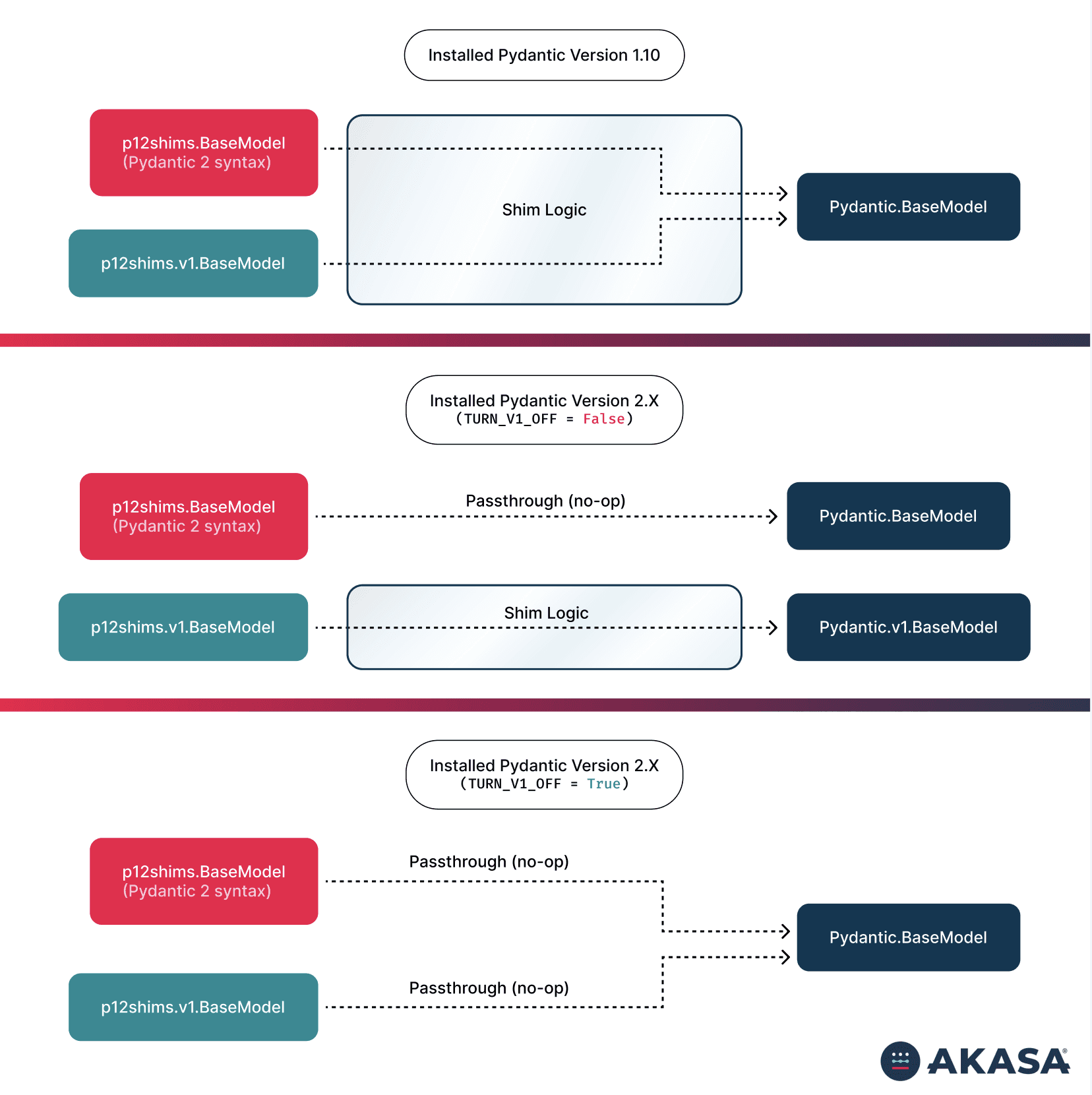
The key shift is that validation is now decoupled from the underlying library version, allowing each part of the system to evolve independently.
Why testing required AI
Deciding how to structure the shim library itself used human judgment. But verifying the shims was pure mechanical coverage: for every feature in the Pydantic 2 migration guide, assert that the shim produces the same behavior as native Pydantic 2.
Here's where the economics of the project changed.
We pointed an AI coding agent (Aider at the time; we'd use Claude Code now) at the official Pydantic 2 migration guide and told it to write assertions covering as many items as possible. The initial implementation was trivial — just re-exporting Pydantic 2 directly — so once the "control" tests passed, it confirmed the tests themselves were correct.
Then we created a separate test configuration running on Pydantic 1, where most of those tests failed. We told the agent to make them pass by implementing shims. The test failures were a specification for what the shim library needed to do, and the agent wrote both sides in sequence.
The result was about 1600 lines of test code running in a GitHub Actions build matrix with three configurations: Pydantic 2 (the control), Pydantic 1 with shims (verifying forward compatibility), and Pydantic 2 with the v1-elimination flag set (verifying that pydantic.v1 imports could be safely replaced).
This would've been tedious to write by hand. Not conceptually difficult, just slow and repetitive — the exact kind of work that's hard to justify when there's a product backlog. AI didn't change what was technically possible here. But even with the relatively primitive AI coding agents of the distant past of (checks notes) last August, it changed the labor cost enough that the project could actually happen.
The same was true for the migration itself. Once the shim library existed and was tested, updating each service was mechanical: (1) change the imports, (2) fix any test failures, (3) ship. It was the kind of work that an AI agent handles well.
Between the shim library making the work decomposable and AI making each piece fast, what had been an intractable coordination problem became a project we could make incremental progress on.
The broader point
Dan Shapiro recently wrote about how AI changes the economics of technical debt.
We think he's right, though we'd frame it more concretely: What changed for us wasn't some abstract interest rate. It's that the labor cost of mechanical code changes — the thing that made this upgrade not worth doing for two years — dropped enough to change the calculus.
The judgment calls (architecture, coordination strategy, what to test) still required experienced engineers. But the volume of tedious, correct code that needed to be produced around those judgment calls shrank from weeks of work to hours.
We're now running our services on Pydantic 2, bringing us up to date and giving access to newer features like Pydantic AI.
This project started as a routine upgrade and turned into a lesson in managing real-world system complexity — where libraries evolve independently, and clean solutions aren’t always available.
It’s also a small example of a broader pattern: building production LLM systems means constantly navigating mismatches between fast-moving tooling and the constraints of real systems.
The interesting work isn’t just in the models. It’s in making the surrounding systems reliable.
These are the kinds of problems we work on every day as we build LLM-powered systems for healthcare: messy, high-stakes, and deeply technical.
If that sounds interesting, we’re hiring.

AKASA
AKASA is a generative AI company helping health systems improve accuracy across the revenue cycle. By building custom large language models for each organization, the platform analyzes the full patient record and surfaces evidence-backed documentation and coding opportunities. AKASA partners with leading health systems, including Cleveland Clinic, to help capture the full value of the care they deliver.







