
Blog
Document Selection for Medical Procedure Authorization
How we built and evaluated a multi-stage ML pipeline to rapidly surface the correct clinical documents for important medical procedures.
The Gist
This blog post breaks down a real-world machine learning challenge: selecting the most relevant clinical documents from large patient encounters to support prior authorization. It explains how the team framed document selection as a relevance and ranking problem, why recall was prioritized over precision, and how a multi-stage pipeline — combining deduplication, lightweight filtering, and fine-tuned language models — improved reviewer efficiency. This piece also shares concrete evaluation methods and unexpected findings from comparing custom-trained models to GPT-based approaches, including why newer models didn’t necessarily perform better.
This post looks back at one of our earlier approaches to automated document selection for prior authorization.
When we first set out to solve this problem, our objective was to develop a reliable system that would have the most significant impact on saving time for physicians and hospital staff. At the time, the latest available OpenAI model was GPT-4, which we could compare against. What follows is a snapshot of that stage of the work that helped us reason about relevance in a practical, production setting.
What Is Prior Authorization and How Did We Approach It?
Prior authorization is a routine part of healthcare operations used by health insurers to review certain medical procedures before they are performed.
For hospital staff (e.g., doctors, nurses, prior authorization teams), this means submitting clinical documentation that demonstrates why a requested procedure is medically necessary for a particular patient. Approval is often required before a procedure can be scheduled or reimbursed, and the outcome of the review determines whether care can proceed as planned or must be delayed, revised, or appealed.
In practice, the responsibility for navigating this process falls largely on health systems and their staff. Physicians and their teams spend an estimated 13 hours per week completing prior authorizations — much of that time devoted to locating and assembling the appropriate documentation.
Although the intent is straightforward, the practical workflow often becomes inefficient. A single patient encounter can generate dozens to hundreds of clinical documents across various categories, including clinical notes, lab results, imaging reports, progress notes, discharge summaries, and more.
Only a small fraction of these documents are typically relevant to the authorization request, yet staff must find a way to sift through the entire set to determine which materials should be submitted. If the correct documents are not submitted, the request may be denied or returned for additional information, introducing avoidable delays for both healthcare providers and patients.
It is not surprising then that 89% of physicians report that prior authorization contributes to burnout, and that 29% say it has led to a serious adverse patient outcome, according to the American Medical Association.
For hospitals and health systems, the challenge is that document relevance is not determined solely by document type or a small set of keywords. It depends on how the clinical details contained in a document relate to the specific procedure being requested and the associated service line. Important information may appear in unexpected places, and documents with similar titles can vary substantially in their clinical significance. As a result, identifying the appropriate documents becomes a careful, time-consuming task that requires contextual understanding.
The approach described here treated this as a relevance classification problem and used a structured, multi-stage system to narrow the search space and apply deeper contextual evaluation.
The pipeline combined deduplication, metadata-based filtering, and a fine-tuned language model trained to assess procedural relevance. Although our current implementation has evolved since this point, the ideas and modeling lessons from this phase were important in shaping how we think about the problem today. The full system from that early iteration is illustrated below.
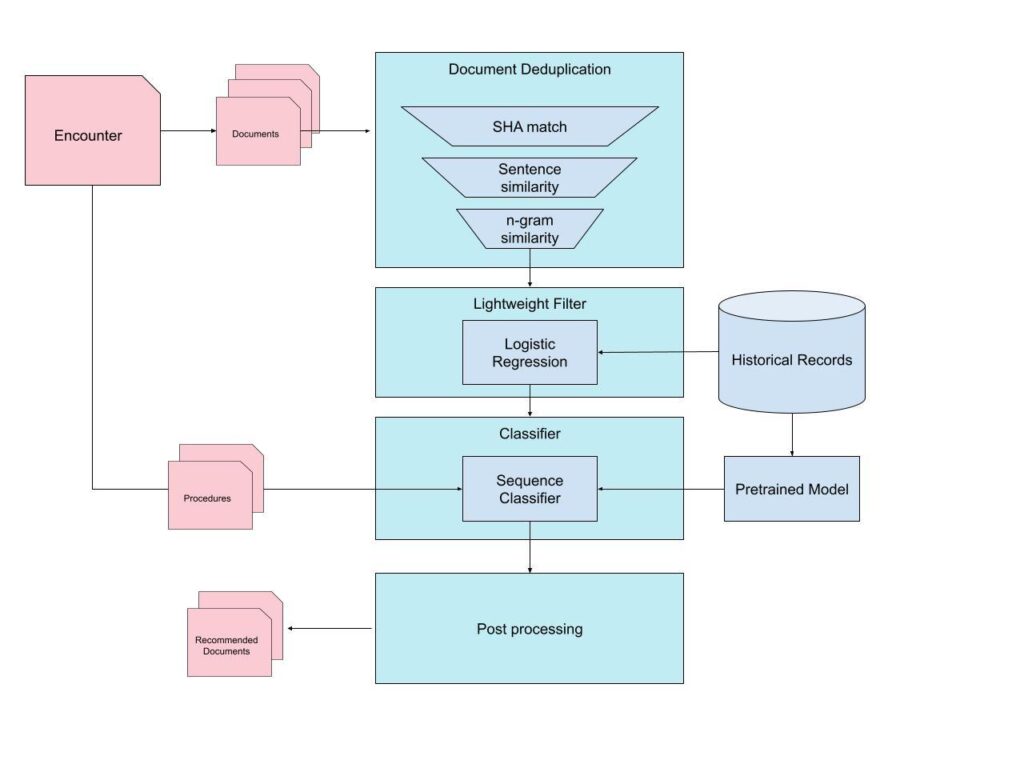
Pre-Filtering
Deduplication
Since some encounters can have many hundreds of documents, it is helpful to narrow down the candidate documents by removing redundancies. Health records frequently have duplicates or near duplicates. This occurs for various reasons, including auto-generated notes, repeated PDF exports, or extracts that differ only in formatting. Therefore, the first stage of filtering involved applying deduplication.
Our deduplication pipeline operated in multiple layers:
Exact-match detection via hashing
The system computed content-level hashes (e.g., SHA-based fingerprints) for each document’s extracted text representation. Identical hashes correspond to exact duplicates and can be removed immediately. This rapid operation eliminated a significant number of redundant files at minimal cost.
Semantic similarity for near-duplicates
Exact matching al
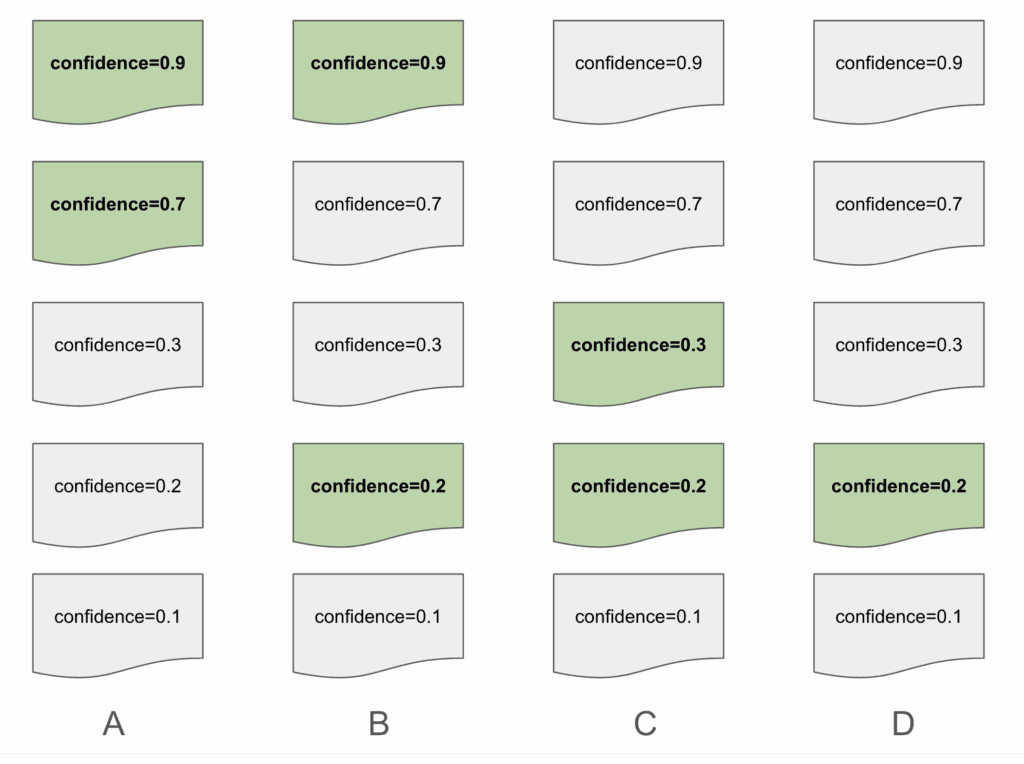
The above is an example of how a list of documents may be presented. The highlighted documents represent a correct “relevant” document, as selected by a human reviewer. Suggestion A has a rank score of 1 because it only has suggestions in the first slots. Suggestion B and C both share a rank score of 0.5. Despite Suggestion B having a correctly predicted document in the first slot, we want to ensure that we are penalizing predictions with relevant documents that were low on the list. Suggestion D results in a rank score of 0.25, with the lowest score of the group due to how far down the list its only suggestions are.
This allowed us to evaluate not only whether the model identifies the correct documents, but also whether it presents them in a position that meaningfully enhances reviewer efficiency, which is ultimately the goal of the ranking stage.
Key Modeling and Evaluation Lessons From Document Selection
Looking back, this pipeline played an important role in defining how we approach document selection as a modeling problem. The work highlighted where lightweight filtering was sufficient, where contextual signals mattered most, and how to evaluate performance in a way that reflected the reviewer experience rather than just raw classification metrics.
The lessons from this phase influenced how we think about model architecture, how we represent clinical information, and how we shape relevance decisions around procedural context.
Over time, those insights led to multiple stages of refinement. While the solution here is an earlier stage in that evolution, it continues to influence the modeling strategies and problem framing that underlie our current system, and represents a key point in the learning process that continues to drive our development efforts forward.
While human review remains an important part of prior authorization, the system has meaningfully reduced the manual effort involved and supported a more consistent and efficient workflow for hospital teams.

AKASA
AKASA is a generative AI company helping health systems improve accuracy across the revenue cycle. By building custom large language models for each organization, the platform analyzes the full patient record and surfaces evidence-backed documentation and coding opportunities. AKASA partners with leading health systems, including Cleveland Clinic, to help capture the full value of the care they deliver.







